DS小入门
本文最后更新于:2024年2月12日 中午
DS小入门
$\mathcal{Author:CoolWind}$
0x00 前言
本文以BUAA22级数据结构课程为基础,进行一个c语言数据结构的入门。
为什么是入门?因为作者太菜进阶不了一点。
本文中只包括数据结构中一些比较大块的东西,包括前置知识准备、线性表、链表、栈和队、树、图、堆六个部分。
作者很菜,如果发现什么错误,请联系我,望各路大佬指正(手动滑鸡)。
同时在这里推荐一些个人认为很好的有助于学习码有关的大佬博客/网站:
0x01 前置知识准备
结构体
什么是结构体?为什么要使用结构体?
结构体可以看做是一系列成员元素的组合体,也可以看做是一种可以DIY的数据类型。
使用结构体可以让你能够在同一个变量中存入不同类型的数据,并且将这些数据放在一起,避免了使用多个数组或者在需要使用同一个“对象”(这里只是一个指代,不是面向对象的对象,因为c不是一个面向对象的语言)的不同类型的性质时所带来的不必要的麻烦。
如何定义一个结构体?
在c语言中,如果需要定义一个结构体,需要使用到struct关键字。
1 | |
以上内容定义了一个数据类型为struct student的结构体(注意带有struct,而不是单纯的student)。
这个结构体中包含了三部分,int类型的id变量,double类型的height变量,char*类型的name指针,以及一个struct student*类型的next_student指针。
虽然结构体的大小在没有声明之前是不固定的,但是在结构体中可以包含一个指向相同类型的结构体指针,因为在同一个计算机中指针所占用的空间大小是固定的。
同理,如果在结构体中声明一个当前结构体类型的变量,会报错
incomplete type,因为当前的结构体类型是不确定大小的。
跟其他数据类型一样,结构体类型的定义可以在全局变量处进行定义,也可以在函数块内进行定义。在全局变量处定义的结构体类型可以在该文件中的所有函数中使用,但是在函数块内(函数大括号内)定义的结构体类型只能在该函数块内进行使用。例如:
1 | |
非结构体的变量类型可以在全局变量处进行变量或者数组的声明,同理,结构体变量类型也可以,例如:
1 | |
typedef的妙用
首先我们要了解什么是typedef。通过typedef我们可以将一个c语言中原有的变量类型或者指针起一个“别名”,例如:
1 | |
如上,可以给long long变量起一个别名叫做ll,也可以给我们自定义的结构体类型struct student起一个别名Student,指针别名为StudentPtr。以上述结构体为例,在进行typedef之后,在声明结构体类型struct student的变量和指针的时候,可以变成如下的方式:
1 | |
注意,在结构体类型定义的时候如果使用了typedef,那么在结构体定义的大括号后面一定要接上你要声明的别名,这个别名可以是变量的别名,也可以是指针的别名,也可以是指针的指针的别名(可以通过
*的个数进行调整,取决于你的需要)。注意,如果你定义了一个指针的别名,例如上文中的
*StudentPtr,你只需要在定义别名的时候这样写,在声明这个结构体指针的时候你只需要写StudentPtr进行声明。如果不小心写成StudentPtr*,那么你声明的就是指针的指针,而不是指针。
这样的别名你可以定义一个,也可以定义多个,例如:
1 | |
如果这样定义,那么student和student2都是这个结构体的别名,都可以用于声明结构体变量。
如何操作结构体变量?
对结构体变量进行操作需要用到两个操作符,.(半角句号)和->(由半角减号-和半角大于号>构成)。
1 | |
上述代码中,我们声明了a这个结构体变量和a_ptr这个结构体指针。对二者操作的时候我们运用了两种不同的操作符。
如果是一个结构体变量,那么我们访问其中的成员并且对其进行操作的时候,需要使用.操作符进行访问。
如果是一个结构体指针,那么我们访问指针指向的结构体变量的成员的时候,需要使用->操作符对其进行访问。此时的a_ptr->name可以等价于(*a_ptr).name,可以理解为一个先取内存后访问成员的过程。
当我们访问到成员之后,就可以对其进行赋值、运算等操作。
快排(qsort)
结构体快排
通过程设的学习我们知道了在stdlib.h库中包含了一个qsort函数,可以用来对数组进行排序。在我们了解了结构体之后,同样的,我们可以对结构体进行排序。
使用qsort函数的关键点在于如何编写cmp函数。下面给出一个用qsort进行结构体排序的例子。
1 | |
以上代码是一段结构体快排的使用实例。qsort需要接收cmp函数的返回值,如果返回值为-1那么就会将满足判断的变量放到后面,如果是1那么就会将满足判断条件的变量放到前面。
因此我们可以用多重的if-else块实现多关键字的排序,上述例子中所表述的就是先根据id成员升序排序,如果id的大小相同,再根据name进行升序排序。
注:
strcmp函数会依次比较两个字符串对应位置的ASCII码值。当第一个字符串大于第二个字符串的时候,返回一个正数;小于,返回一个负数;相等,返回0。注:
cmp函数中aa和bb指针的声明其实可以省略。如果没有声明这两个变量,那么下面的所有if部分都需要使用(student*)a和(student*)b代替。
使用结构体快排让qsort存在稳定性
知周所众,qsort是一个不稳定的排序,那么如何让qsort变得存在稳定性呢?
我们可以使用结构体,在结构体中插入一个int类型变量(假设名为id)来记录这个元素在结构体数组中本身的序号,然后使用结构体的多关键字排序,第二关键字以id做升序排列,这样就实现了qsort的稳定性。
当然这个操作也可以使用二维数组完成。
文件IO
在数据结构的学习中,我们经常要让我们的程序与外界的文件进行读取写入,这里我们称之为文件IO。
首先我们需要认识一下专门用于文件操作的变量FILE。这是一个定义在stdio.h里的一个结构体变量,它储存了一个文件中包含的一系列信息。而我们操作文件主要是通过文件指针,也就是FILE*。
然后我们需要认识一下常用的文件操作的函数:
fopen
fopen(char *file, char *open_mode);
用于打开文件,返回FILE*,参数是需要打开文件的名称以及想要打开的方式。
文件名称可以是绝对路径(从盘符开始),也可以是相对路径(相对于代码所在文件夹)。
打开方式可以参照如下表格:
| 文件使用方式 | 含义 | 如果指定文件不存在 |
|---|---|---|
| “r”(只读) | 为了输入数据,以文本形式打开一个已经存在的文本文件(从文件获取) | 出错 |
| “w”(只写) | 为了输出数据,以文本形式打开一个文本文件(向文件输出) | 建立一个新的文件 |
| “a”(追加) | 向文本文件尾添加数据 | 出错 |
| “rb”(只读) | 为了输入数据,以二进制形式打开文件 | 出错 |
| “wb”(只写) | 为了输出文件,以二进制形式打开文件 | 建立一个新的文件 |
| “ab”(追加) | 以二进制形式打开文件并向文件尾添加数据 | 出错 |
| “r+”(读写) | 为了读和写,以文本形式打开一个文本文件 | 出错 |
| “w+”(读写) | 为了读和写,创建一个新的文本文件 | 建立一个新的文件 |
| “a+”(读写) | 打开一个文件,在文件末尾读进行读写 | 建立一个新的文件 |
| “rb+”(读写) | 为了读和写打开一个二进制文件 | 出错 |
| “wb+”(读写) | 为了读和写,以二进制形式新建一个文本文件 | 建立一个新的文件 |
| “ab+”(读写) | 打开一个二进制文件,在文件末尾进行读和写 | 建立一个新的文件 |
其中所有带
r和a的操作都不会清空被操作文件,但是带w的会清空被操作文件。
fread
fread(void *buffer, size_t size, size_t count, FILE *stream);
用于从指定文件中读取对应个数的指定单元。
buffer传入接受指定单元类型的数组;size传入要读取的指定单元的字节数,一般使用sizeof运算符获取,例如sizeof(char);count传入要读取的指定单元的个数;stream为已经通过fopen打开的FILE*指针。
fwrite
fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
用于向指定文件中写入对应个数的指定单元。
ptr指向想要写入的数据数组;size是指定单元的字节数;nmemb是想要写入的指定单元的个数;stream为已经通过fopen打开的FILE*指针。
fgets
fgets(char *str, int n, FILE *stream);
用于从指定文件中读取对应个数的字符。
str指向想要写入数据的char数组;n表示最多读取n-1个字符;stream为已经通过fopen打开的FILE*指针。
fputs
fputs(const char *str, FILE *stream);
用于向指定文件中写入一个字符串。
str指向想要写入的char数组;stream为已经通过fopen打开的FILE*指针。
fgetc
fgetc(FILE *stream);
用于从指定文件中读取一个字符。
stream为已经通过fopen打开的FILE*指针。
fputc
fputc (int c, File *fp);
用于向指定文件中写入一个字符。
c为想要写入的字符的ASCII码;stream为已经通过fopen打开的FILE*指针。
fseek
fseek(FILE *stream, long offset, int fromwhere);
用于移动文件指针。
stream为已经通过fopen打开的FILE*指针;offset为设置的偏移字节,可以为正数或者负数;fromwhere为设定文件指针的起始位置,有三种选择:
| 宏名称 | 表示含义 | 代表的数字 |
|---|---|---|
| SEEK_SET | 文件头 | 0 |
| SEEK_CUR | 当前位置 | 1 |
| SEEK_END | 文件尾 | 2 |
fclose
fclose(FILE * stream);
用于关闭文件流。
stream为已经通过fopen打开的FILE*指针。
内存管理
在不考虑速度的情况下,我们可以使用如下几个函数来分配内存。
malloc
malloc(unsigned int num_bytes);
分配指定大小的字节块,返回一个指向该字节块头的指针。
num_bytes是需要分配的字节大小,一般设置为sizeof(yourType)*num。
注意,malloc返回一个
void类型指针,因此使用的时候需要进行类型转换,例如(yourType*)malloc(sizeof(yourType)*num)
calloc
calloc (size_t num, size_t size);
分配指定大小的字节块,并且初始化为0,返回一个指向该字节块头的指针。
num为想要分配的指定类型的数量,size为指定类型的字节数。
free
free(void *ptr);
释放指针指向的内存块。
ptr是一个指向由malloc,calloc分配的内存块。
0x02 线性表
什么是线性表?有什么特点?
数据元素之间具有逻辑关系为线性关系的元素集合称之为线性表。
线性表具有以下三个特点:
- 同一性:所有的元素都是同一个数据类型。
- 有穷性:只能存储有限个数据元素。
- 有序性:相邻元素有着前后的顺序关系。
在c语言中,数组是一种常见的线性表。
线性表的查找-二分查找
将遍历查找的O(n)算法降低为O(logn)算法,但是需要先对线性表进行排序。原理是通过比大小取中值最终找到想要找到的值,每次对当前段进行二分。
实现代码如下:(来自亲爱的学长$\mathcal{Only(AR)}$)
分为以下三种:
- 基础版(只返回找到的位置,找到谁算谁)
- 下边界版(找到第一个大于等于目标的)
- 上边界版(找到第一个大于目标的)
!!牢记是否取等,加一减一!!
1 | |
练习题
0x03 链表
终于,我们进入了DS的核心之一,链表。
什么是链表?为什么要使用链表?
链表是一组地址任意的存储单元(连续的或不连续的)依次存储表中各个数据元素, 数据元素之间的逻辑关系通过指针间接地反映出来。
可以使用不连续的存储单元编写链表,也可以使用数组来模拟链表。以下内容以不连续的存储单元为例。
相对于静态的线性表,链表是一个动态的结构,它的好处有:
- 节省空间,在使用的时候申请空间,防止因为申请空间过多导致储存空间的浪费。
- 让插入元素变得更加方便,在线性表中,我们要在一个已经被填充的表的表中间特定位置插入特定元素需要先遍历该位置之后的元素,将他们向后复制一位,然后再进行插入,这样才能保证表的完整。但是在链表中,我们只需要新申请一个空间,然后修改指针指向即可。
- 让删除元素变得更加方便,同理,删除元素是插入元素的逆操作,使用链表也可以简单的删除已经被填充的表的表中间特定位置的某个元素。
链表结点的定义与创建
链表的每一个结点是一个结构体,例如上文中的例子:
1 | |
就可以称之为一个链表的单元,包括了想要携带的数据以及指向下一个(以及上一个)结点的指针。
注:结点指针必须写类似
struct yourStructName*的格式,具体原因见上文。
同时,我们可以将创建结点打包为一个函数。
1 | |
链表的分类
链表可以分为如下几种:
单向链表:最简单的链表,每一个结点都指向下一个结点

双向链表:顾名思义,可以从前到后,也可以从后到前

循环链表:单向链表头尾相接,构成一个环

双向循环链表:双向链表头尾相接,构成一个环

链表操作
以下只以单向链表和单向循环链表为例,双向链表与单向链表基本相同,主要区别就是两个指针的指向需要注意。
单向链表
链表插入
链表插入的过程如下:
- 申请一个结点的空间,获取其指针,并且设置其携带数据。
- 从头结点开始遍历,找到尾结点(指针指向NULL)。
- 将新结点中的连接指针指向尾结点指向的指针。
- 将尾结点中的连接指针指向新结点。
在链表的插入中,我们默认头结点存在;如果不存在,可以进行一次判空,先创建头结点之后再进行插入。
1 | |
链表插入函数的更多问题可以参考前言中DS-bug全扫除计划。
链表删除
链表删除的过程如下:
- 从头结点开始遍历找到符合条件的目标结点的前一个结点。
- 将目标结点的前一个结点的连接指针指向目标结点的后一个结点(目标结点的连接指针)。
- 释放目标结点的空间。
1 | |
可以释放也可以不释放,看自己心情;只要将目标结点的前一个结点的指针指向目标结点的后一个结点,目标结点就已经不在链表中,等效于从链表中删除了这个结点。
链表查找
链表查找的过程如下:
- 从头结点开始遍历找到符合条件的目标结点。
- 返回指向目标结点的指针。
1 | |
单向循环链表
在循环链表中,头结点的连接指针指向自身。
这里只展示链表插入时的区别,查找和删除与插入雷同。
链表插入
链表插入的过程如下:
- 申请一个结点的空间,获取其指针,并且设置其携带数据。
- 从头结点开始遍历,找到尾结点(指针指向头结点)。
- 将新结点中的连接指针指向尾结点指向的指针。
- 将尾结点中的连接指针指向新结点。
1 | |
总结
链表是数据结构中很重要的一个部分,虽然链表有很多分类,但是不同种类的链表的区别也就只在于储存了链表的一端还是两端,链表中结点包含的指针是只指向下一个结点还是指向前后两个结点,尾结点是否指向头结点这三个部分。
练习题
0x04 栈和队
什么是栈和队?有什么用?
栈和队是一种相对抽象的数据结构,换言之,栈和队的概念和操作比如何实现更加重要。
形象的来说,栈类似一个桶,是一个下方封闭上方打开的结构,数据只能从开口处被放入和取出,因此,对于栈中所储存的所有元素,先进入栈的后被弹出,后进入栈的先被弹出;而队类似一个管子,是一个两端开口的结构,假设为头和尾,那么数据只能从尾部放入,从头部取出,因此,对于栈中所储存的所有元素,先进入队的先被弹出,后进入队的后被弹出。
我们可以使用数组来实现栈和队,也可以通过链表来实现,但是推荐使用数组,因为更加简单直观,以下都为使用数组来实现。
利用栈和队,我们可以轻松的实现数据的后进先出(last in first out - LIFO)和先进先出(first in first out - FIFO),让我们在存储调用数据和模拟更加方便。
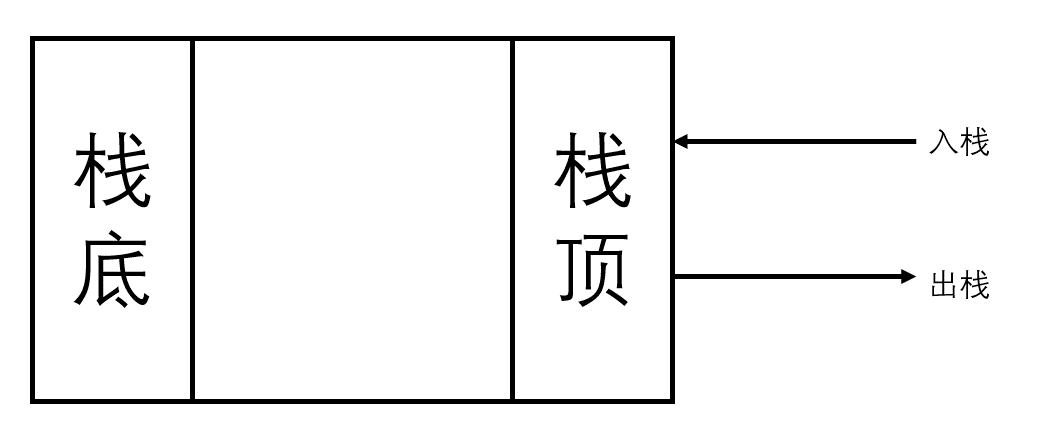
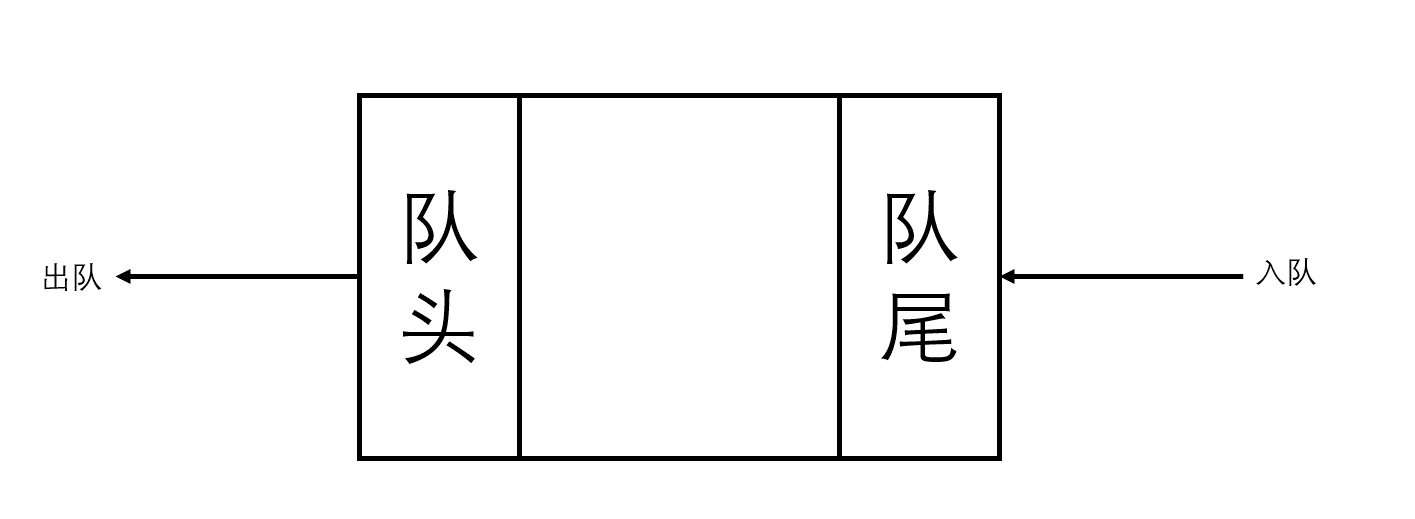
栈的操作
栈的操作主要分为如下几种:
压栈
将一个数据写入到栈顶位置,然后将栈顶指针(数组下标)加一。
弹出
将栈顶的数据弹出,将栈顶指针(数组下标)减一。
查看栈顶元素
返回当前栈顶指针(数组下标)所指的元素(栈顶元素)。
查看栈是否为空
判断当前栈顶指针是否为0。
封装为函数使用
1 | |
队的操作
队的操作与栈相似,分为以下几种:
入队
将一个数据写入队尾,然后让队尾指针(数组下标)加一。
出队
将队头指针(数组下标)加一。
返回队头元素
返回队头指针(数组下标)指向的元素。
判断队列是否为空
返回队头指针(数组下标)和队尾指针(数组下标)的差是否为0。
封装为函数使用
1 | |
循环队列
在使用上述队列的时候我们可以发现,在不进行其他归零操作的情况下,队头指针和队尾指针是在不断右移的,如果入队出队操作次数过多,可能会导致大量的空间浪费或者数组越界。(虽然这个问题在数据量较小的时候可以使用加长队列长度来解决)
因此,我们可以使用循环队列来解决这个问题。
所谓循环队列,就是用取模运算将一定队列长度的数据限制在一个固定长度的队列中,显然我们可以使用取模运算%来实现这一点。
循环队列并不是一个无限长的队列,只是能够充分利用固定大小的数组实现队列操作。
循环队列中能存储元素的个数
作业中有这样一道题:
描述某循环队列的数组为QUEUE[0..M-1],当循环队列满时,队列中有()个元素
这道题的答案是M或M-1个元素。
这取决于是否有标记来进行队满的判断,因为在循环队列的实现中,如果没有记录当前队列长度,当队尾指针等于队头指针的时候,我们无法判断是队空还是队满,此时我们只能认为队满是(queueTail+1)%QueueLength == queueHead的时候,即队列中有QueueLength-1个元素;如果记录了当前队列长度,可以通过队列长度进行判断是队满还是队空,即队列中有QueueLength个元素的时候是队满。
封装为函数使用
以下为记录当前队列长度时的循环队列实现。
1 | |
0x05 树
什么是树?
上文中我们提到的数组、链表、栈和队都是一种线性结构,除了头部和尾部都有唯一的前驱和后继。那么,如果我们给一个结点定义不止一个后继指针,我们就形成了一个树状结构;换句话说,树是一个分叉的链表。
在ds课中,我们经常用到的是二叉树,当然还有很多种树的类型,可以参考oi-wiki-数据结构。下面我们都基于最简单实用的二叉树-BST(二叉搜索树)来进行叙述。
什么是BST?
BST(二叉搜索树)是一种具有特殊限制的树结构。对于BST中的每一个结点,它的左儿子结点携带的数值小于它,它的右儿子结点携带的数值大于它。
如何定义和创建BST结点?
上面我们已经提到,树与链表十分相似,因此我们可以类比链表的结点定义和创建方式来进行树结点的定义和创建。
1 | |
BST的操作
结点插入
对于BST结点的插入,可以使用递归的方法,同时判断想要插入的数值与结点中所携带数值的大小,根据自己建立的BST的规则判定是继续递归或者返回。
1 | |
以下是插入时的过程。假设我们要将一个数据15插入到如图所示的BST中。
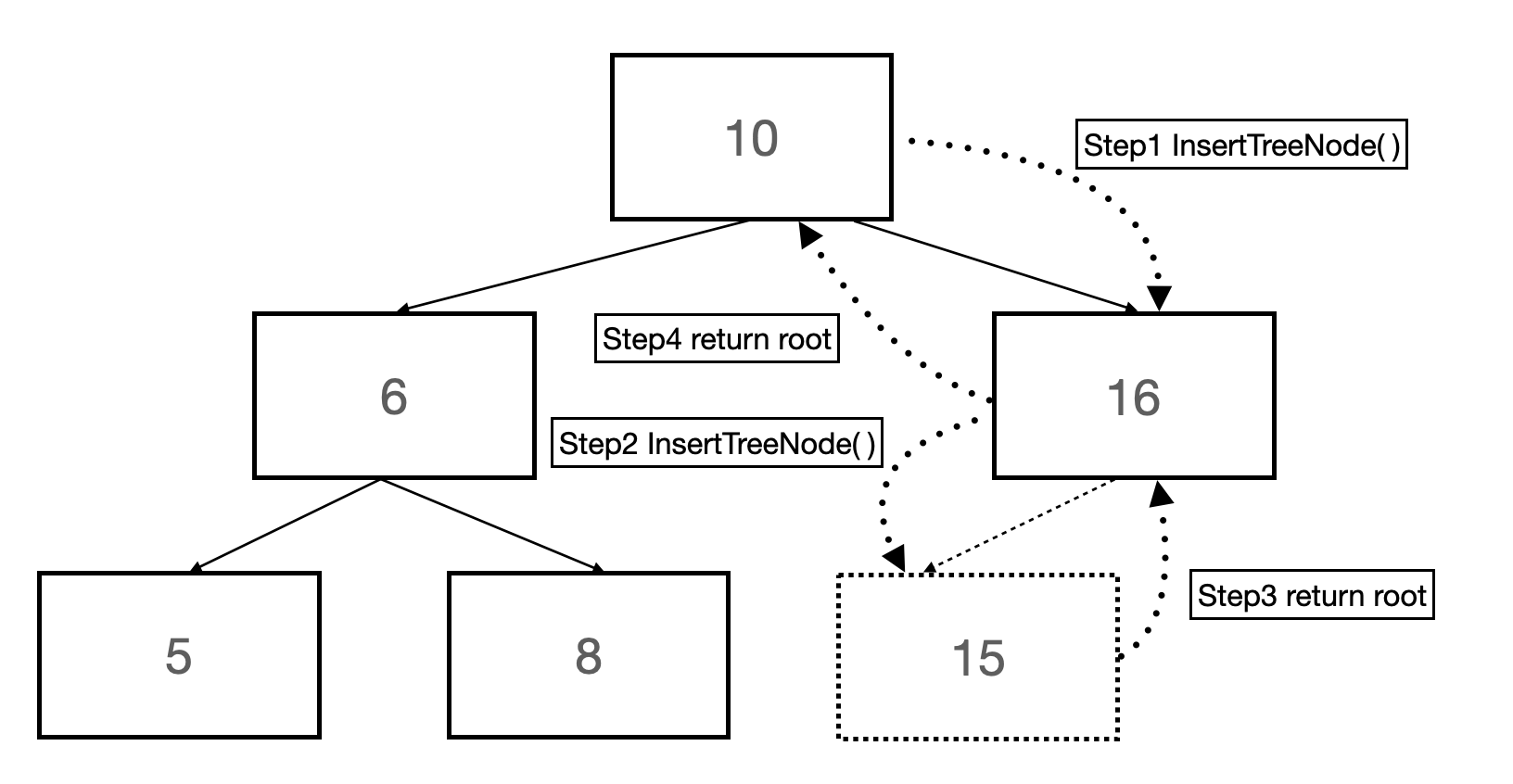
上图显示了将一个结点插入BST中时的递归情况,建议大家配合调试食用(绝对不是我懒得画动图)。
结点删除
在树中删除一个值为value的结点,分为以下几种情况:
- 如果结点的
cnt大于1,只需要将cnt减1 - 如果结点的
cnt等于1:- 如果该结点为叶子结点(左右子结点都为空),那么直接删除这个结点
- 如果该结点只有一个子结点,那么用这个子结点代替本身
- 如果该结点的左右子结点均不为空,那么用它的左子树的最右结点(最大的小于自身的结点)或者右子树的最左结点(最小的大于自身的结点)代替它本身,这样可以维持BST的结构。
代码实现如下(使用左子树的最右结点进行处理)
1 | |
结点查找
结点查找的内容已经包含在结点插入和删除中了,即为通过比较所要查找的数据以及当前结点的数据值进行查找。由于查找的过程是一个尾递归的过程,因此我们可以使用循环来代替。这里给出一个通过循环进行结点查找的代码实例。
1 | |
个人认为循环比递归好理解多了QAQ。
BST的遍历
遍历树的每一个结点是树结构的一个很重要的内容,在这里我们以上文中已经构建的BST为例进行说明。
前序遍历
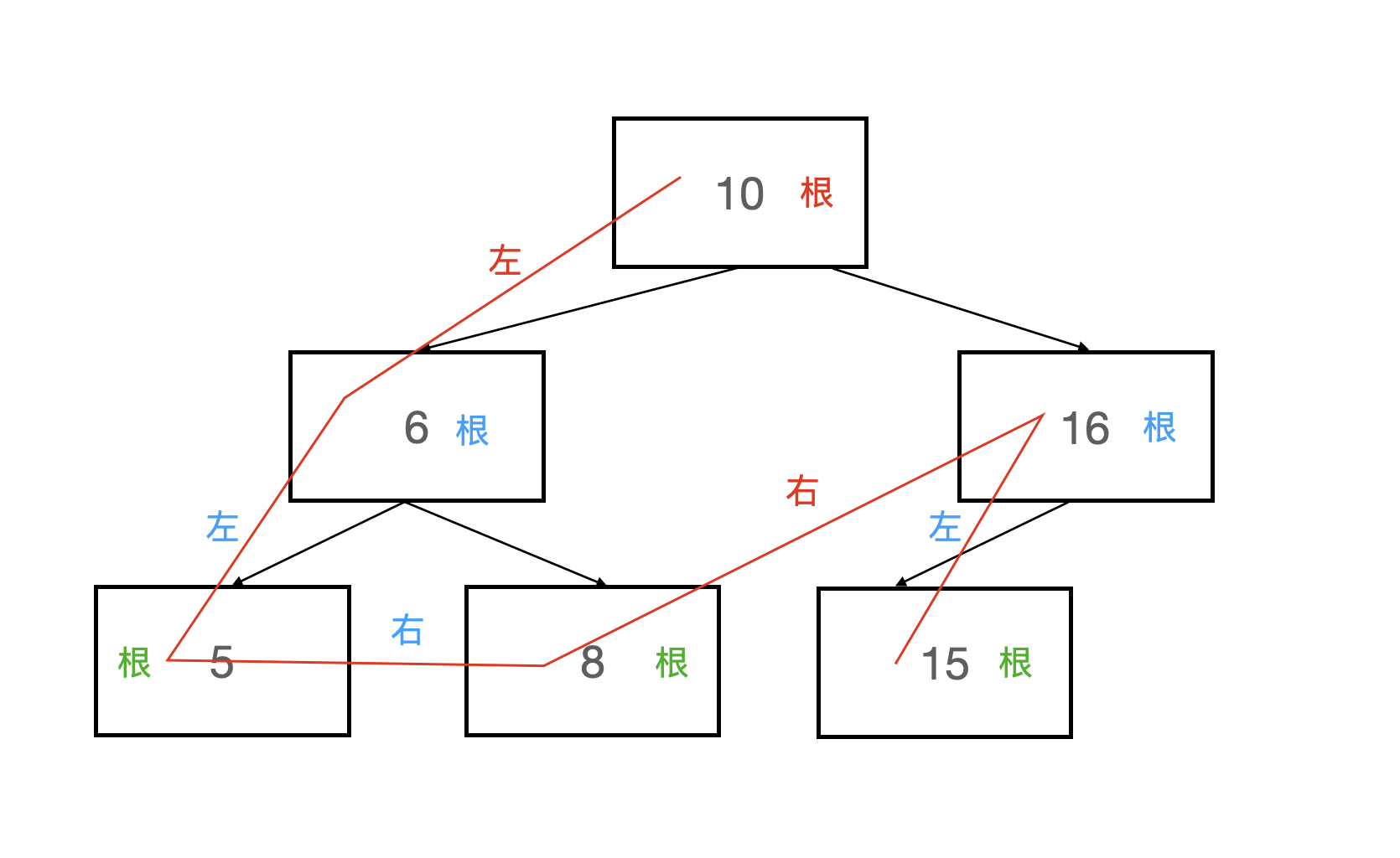
前序遍历按照“根-左-右”的顺序将树中所有的结点进行输出,代码实现如下:
1 | |
可以理解为,从根结点开始,先输出自身,然后输出自身的左儿子,再输出自身的右儿子,直到遍历整棵树。
图片解释如下,其中相同颜色代表一组“根-左-右”,红色线代表遍历的轨迹。
遍历结果为:10 6 5 8 16 15
中序遍历
中序遍历按照“左-根-右”的顺序遍历整棵树,代码实现如下:
1 | |
图片解释如下:
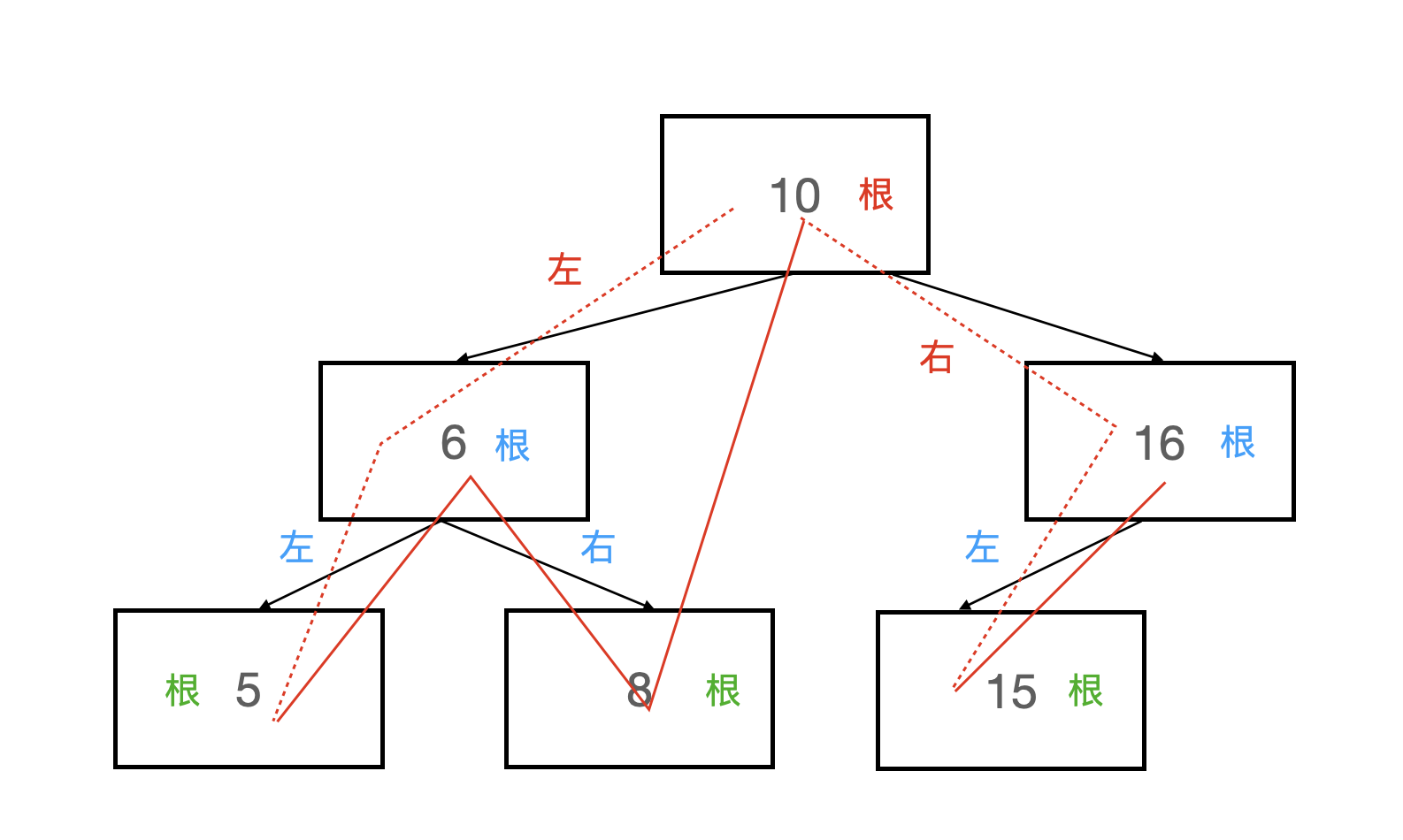
中序遍历结果为5 6 8 10 15 16
图片中所有红色线表示遍历的过程,红色虚线代表递归到该结点但是没有执行printf,红色实线代表了打印的顺序。
跟着红色线的轨迹进行遍历可以发现,对于每一个根结点,其结点的打印顺序都是“左-根-右”,只是如果左/右结点不是叶子结点的时候,会在中间插入以其左/右结点为根的子树的中序遍历,并依此方式遍历整棵树。
后序遍历
后序遍历以“左-右-根”的顺序遍历整棵树,代码实现如下:
1 | |
图片解释如下:
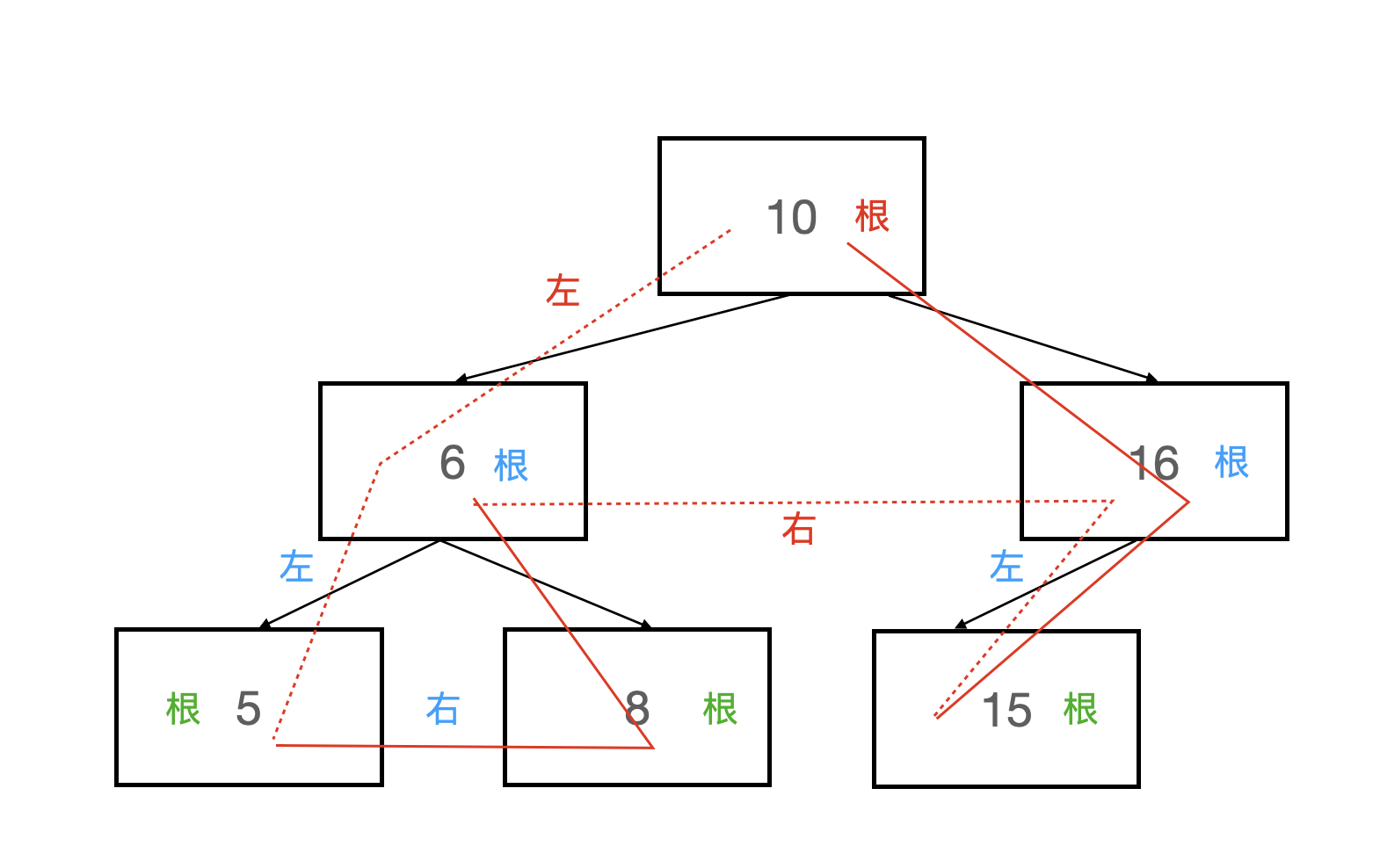
后序遍历结果为5 8 6 15 16 10
与中序遍历相似,后序遍历对于每一个根结点来说,遍历顺序都是“左-右-根”,只是在其中递归的插入了非叶子结点的子结点的后序遍历结果。
层序遍历
所谓层序遍历,就是按照树的分层进行遍历。例如在上图所构建的二叉树中,层序遍历的结果应该为10 6 16 5 8 15。
我们会发现,这样的顺序等价于从根结点开始,先出现的结点先输出,这与我们上文中说过的FIFO(先入先出)结构相似,那么我们就可以用队来解决这个问题。
只要我们从根结点开始,首先输出根结点的数据,然后将这个根结点的左右子结点按次序入队,之后每一次输出队头结点存储的数据输出,再将其左右结点压入队中,我们就能够很容易的实现树的层序遍历。
代码实现如下:
1 | |
代码输出为10 6 16 5 8 15
用循环实现,首先将根结点压入队中,然后循环“输出队头结点-队头结点出队-压入非空左儿子结点-压入非空右儿子结点”这一过程,直到队列为空。
数组模拟二叉树与LCA问题
数组模拟二叉树
虽然用指针实现的二叉树较为形象,但是动态分配内存需要花费较长时间,并且如果想要实现从子结点直接查询父结点需要双向的指针,操作较为繁琐。因此我们可以使用数组进行二叉树的模拟。
根据二叉树的结构我们可以知道,如果规定根结点的深度是0,那么深度为n的结点共有$2^n$个,因此我们可以将二叉树在数组中进行表示。
在用数组表示二叉树的时候,若父结点的数组下标是a,那么左右子结点的下标分别为2a,2a+1。以树的插入为例给出以下代码实例:
1 | |
什么是LCA问题?
LCA(最近公共祖先)问题是树上一个比较经典的问题,这里我们只介绍朴素算法,更多快速算法请参考oi-wiki-LCA。
朴素算法的思想是通过存储在结点中的深度,每次让深度更深的结点向上查找父结点,直到两个结点访问到同一个父结点。
代码实现如下:
1 | |
每次将更深的结点向上拉,最终可以得到公共祖先。
总结
树的种类有很多,但是基础的操作与BST基本没有差异,掌握好BST即掌握了树的大部分知识。